アップローダーを使用すると、値を手動で入力する代わりに、生の装置ファイルを直接Uncountableにドラッグ&ドロップできます。アップローダーは、生ファイルから数値や曲線の出力、条件パラメータ、メタデータなど、さまざまな種類のデータを抽出するために使用できます。
データをアップロードするには、実験アウトプットビューでUpload Dataモーダルを使用します。ファイルをドロップすると、アップローダーが値を解析します。承認されると、そのデータは実験にインポートされます。ただし、アップローダーがデータを解釈し、マッピングするには、初期設定が必要です。
アップローダーの設定は通常、Uncountable担当者によって行われます。ただし、本記事ではその設定の仕組みと、独自のマッピングを構築する方法について説明します。
生ファイル
Uncountableのアップローダーは、複数のタブにデータが含まれる一般的なExcelファイルや、シンプルなテキストエディタで開けるファイル(.txt、.csv、.xlsx、.rtf、.dat)を解析できます。ファイルは機械で読み取るため、.pdfなどの形式はサポートされません。
通常、使用される機械ファイルは次の2つの主要なコンポーネントで構成されます。
- ヘッダー:ファイル名、使用した機器、オペレーター、実行日など、ファイル全体に適用される情報を含みます。ヘッダーフィールドは、1つのフィールド名と1つの値のペア(1:1 フィールド:値)で構成されます。
- ファイル構造:ファイル構造は、レシピデータの自己完結型ブロックで、チャンネルごとに整理されています。
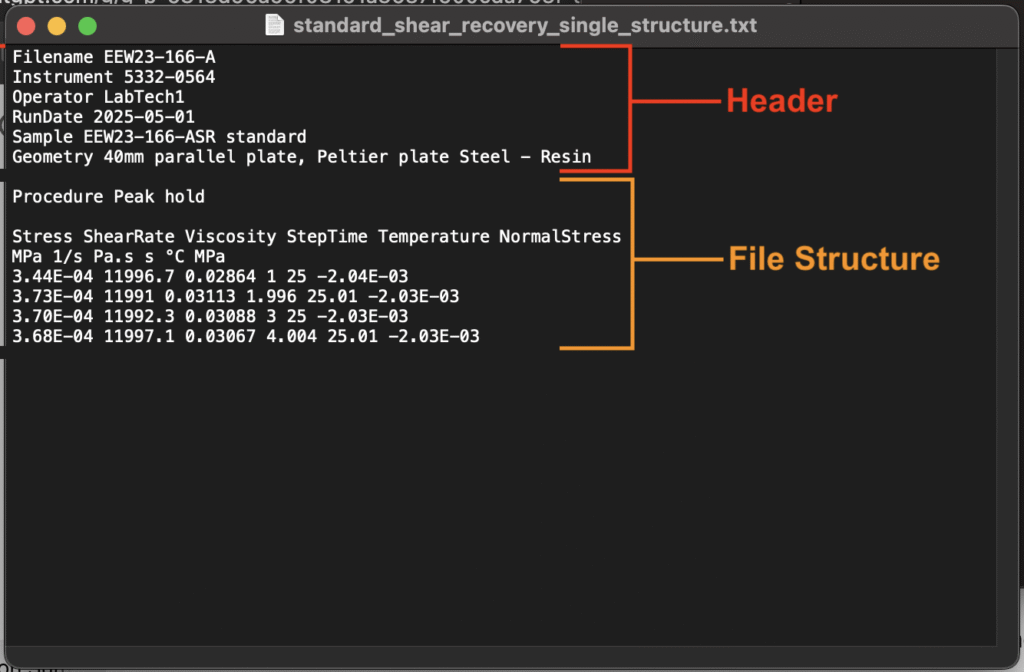
ファイル構造
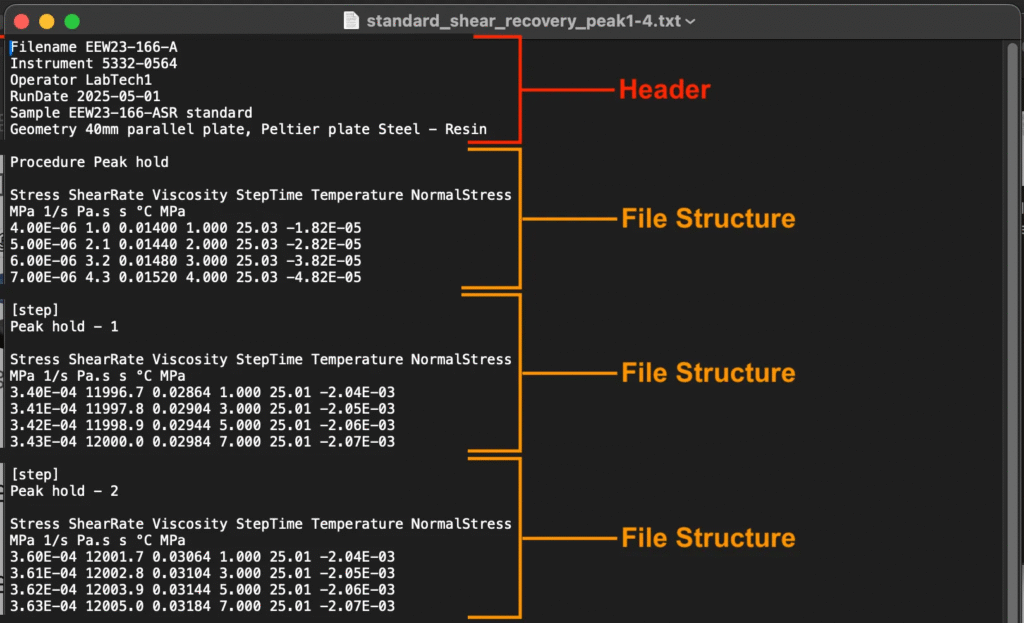
ファイルには1つ以上のファイル構造が含まれます。ファイル構造には、実際に測定されたデータが含まれ、次の要素で構成されます。
- ヘッダー:ファイル構造全体に適用される情報を含みます。ヘッダーは通常、最初の数行または列にあり、シンプルな1:1のフィールドと値の形式に従います。ファイル構造内では、ヘッダーに条件パラメータ、出力メタデータ、または変換情報が含まれることがよくあります。
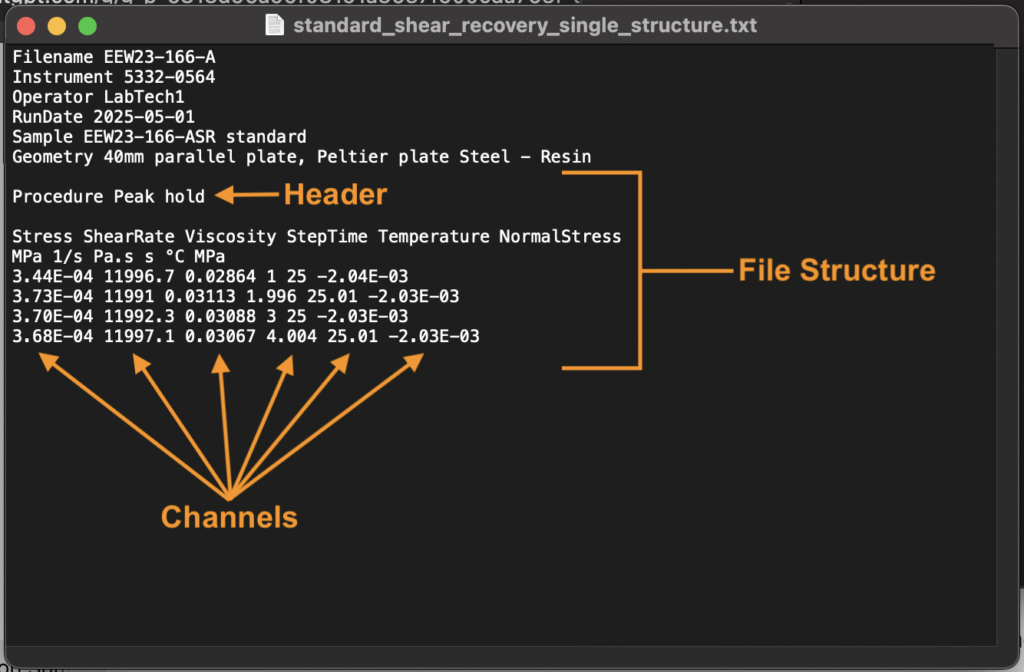
- チャンネル:実際に測定された値を表し、行または列に整理されます。チャネルは、名前、数値データ配列、およびオプションの単位で構成されます。主なタイプは次の2つです。
- 数値チャンネル:測定値の単一リスト(例:粘度)。 曲線チャンネル:ペアになった値のリスト(例:時間と力)。
- 1つのチャンネルを最大値に縮小する(
1チャンネル→1数値)。 2つのチャンネルを処理して、ピークy値におけるx値などを抽出する(2チャンネル→1数値)。
ファイルには複数のファイル構造が含まれる場合もあります。1つのファイルに複数のファイル構造が含まれるケースとして、次のようなものがあります。
- レプリケート:複数のレプリケートが1つのファイルに保存されている。
- フェーズまたはステップ:1つの実験が連続するフェーズに分割され、それぞれが独自の曲線として記録されている。
- 条件設定:異なる条件パラメータで記録された複数の曲線。
デフォルトでは、アップローダーは異なるファイル構造をレプリケートとして扱います。ただし、マップファイル構造の設定を使用することで、この動作をカスタマイズできます。詳細はこちらをご覧ください。
アップローダーの構築方法
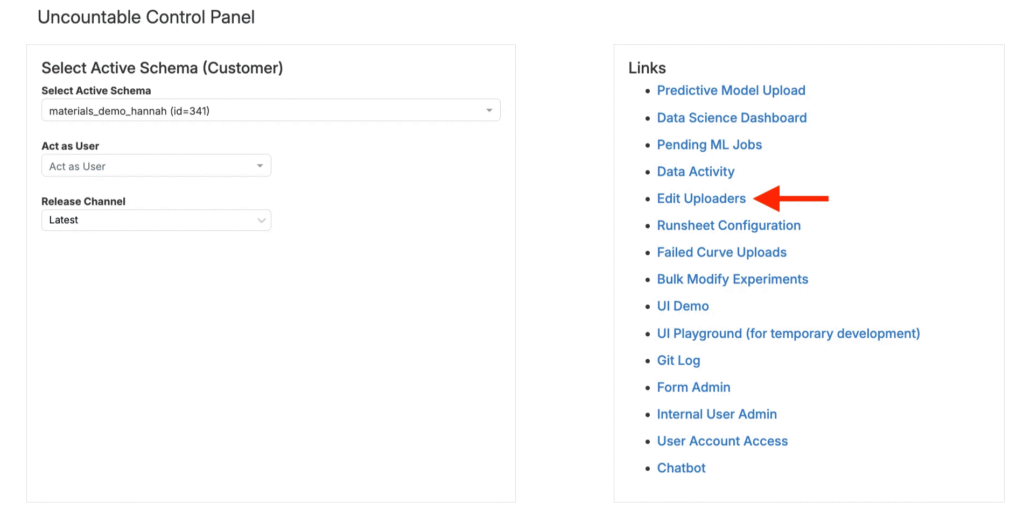
ステップ1―新しいアップローダーを作成する
アップローダーは、コントロールパネルの「アップローダーを編集」ページで作成します。
ステップ2―サンプルファイルを読み込む
アップローダーを構築するには、まず設定対象となるサンプルの生ファイルが必要です。サンプルファイルを「サンプルファイル」フィールドに直接ドラッグ&ドロップしてください。これは、ユーザーがプラットフォームにアップロードする予定のファイルタイプを代表する実際のファイルである必要があります
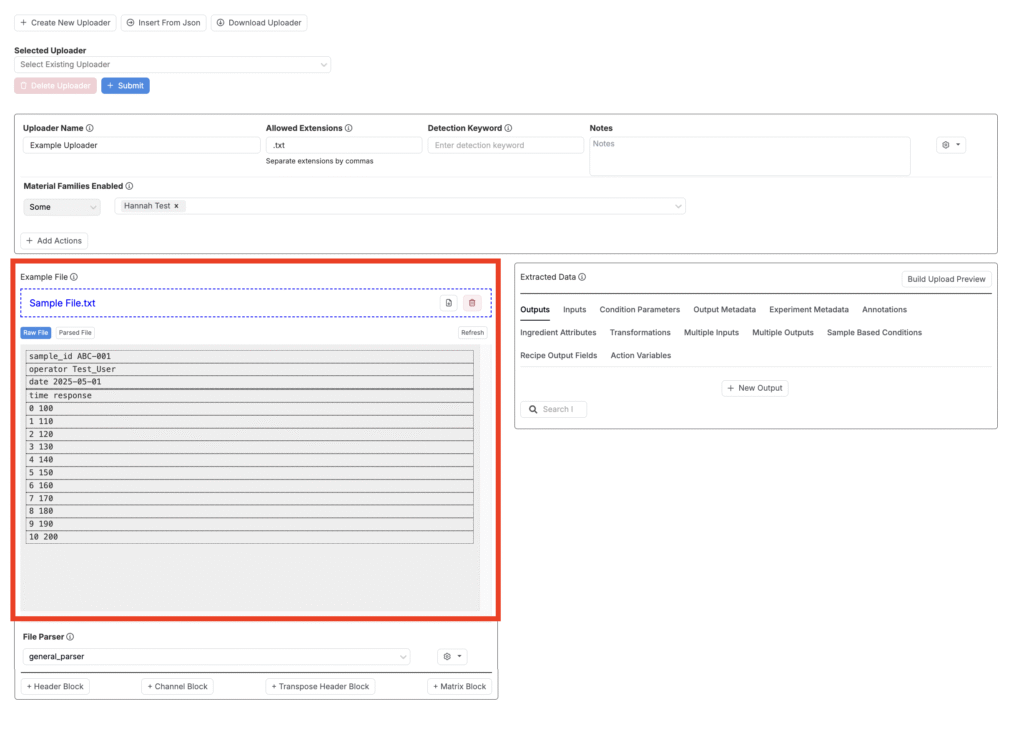
ステップ3―アップローダーの設定
サンプルファイルを読み込んだら、次の情報を入力します。
- アップローダー名:わかりやすく、説明的なラベルを追加します。
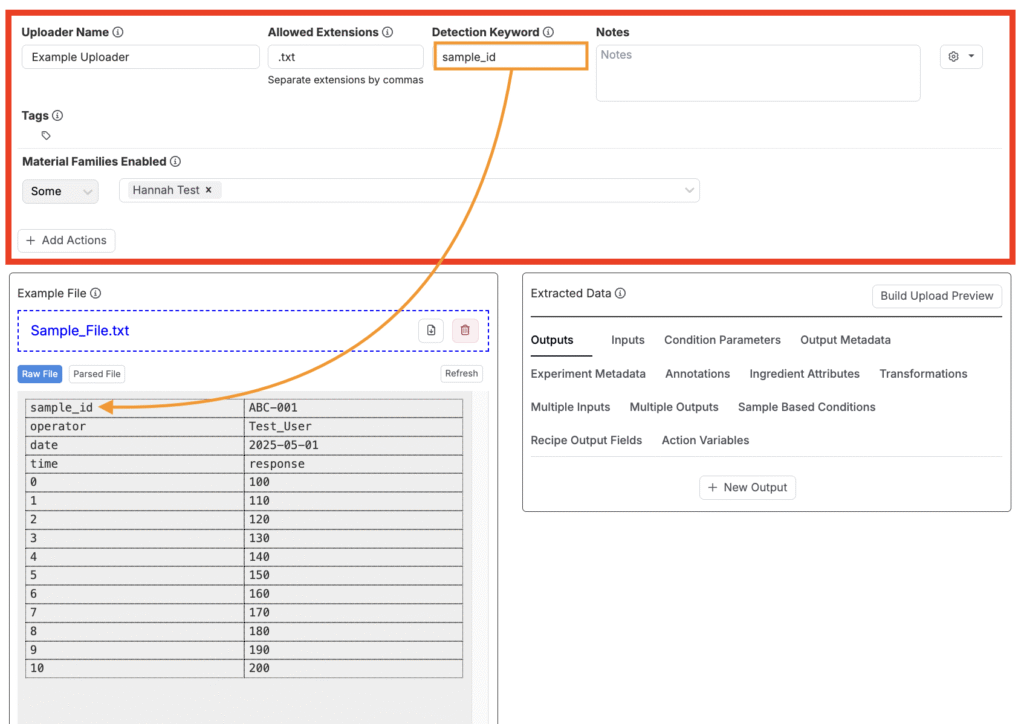
- 許可されている拡張子:このアップローダーが受け入れるファイルタイプをカンマ区切りで記載します(例:
.txt、.csv)。 - 検出キーワード:このタイプのすべてのファイルに含まれる固有の単語またはフレーズを選択します。プラットフォームはこのキーワードを使用して、アップロードとアップローダーを一致させます。
- メモ:機器の詳細、バージョン情報、管理者向けのヒントなど。
- 材料ファミリの有効化:このアップローダーを表示するファミリを選択します。
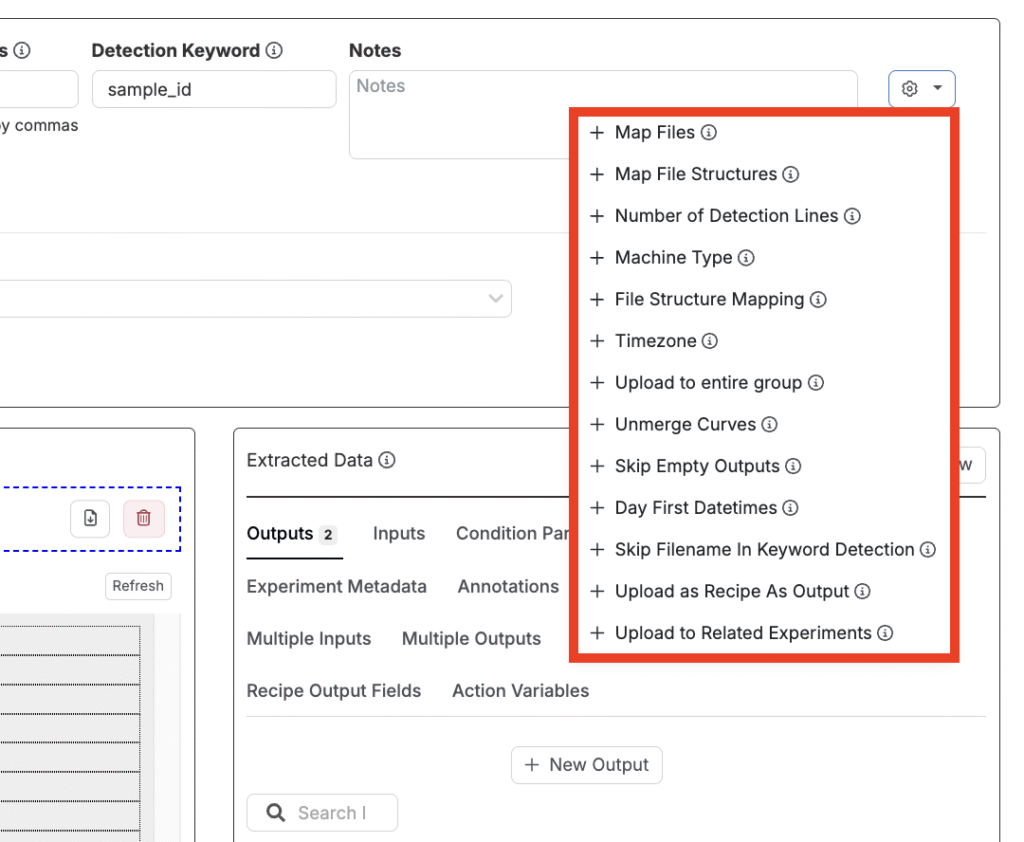
アップローダー設定メニューには、次のような追加設定もあります。
- マップファイル:アップローダーは、同じファイルタイプの複数ファイルを一度にアップロードできます。マップファイルの設定では、アップローダーがこれらのファイルをどのように処理するかを定義できます。選択肢には、「to replicates (デフォルト)」、「to recipes」、「custom」、または「none」が含まれます。詳細はこちら。
- マップファイルの構造:ファイルに複数のファイル構造が含まれる場合、マップファイルの構造設定でアップローダーがそれらをどのように扱うかを定義できます。選択肢には、「to replicates (デフォルト)」、「to recipes」、「custom」、または「none」が含まれます。詳細はこちら。
- 検出ラインの数:アップローダーが検出キーワードを検索する行数を設定します(デフォルトは15行)。キーワードがファイルの後半にある場合に便利です。
- 機会の種類:アップローダーを特定の機器に関連付けます。
- ファイル構造マッピング:ファイル構造をUncountable内の既存処方に自動マッピングします。詳細はこちら。
- タイムゾーン:このアップローダーで解析された日付に適用するタイムゾーンを選択します。
- グループ全体へのアップロード:ターゲット実験と同じグループ内のすべての実験にアップロードするかどうかを設定します。
- 曲線のマージを解除:アップロード中に結合された曲線を分離します。
- 空のアウトプットを省略:空のアウトプットをスキップするように指示します。
- 1日目日時:日付を日→月→年の順で解析する設定を有効にします(例:1/6/2025は6月1日)。
- キーワード検出でファイル名を省略:アップロードされたファイルで検出キーワードを検索する際にファイル名をスキップします。
- 方策をアウトプットとしてアップロード:処方にアップロードされた入力は、内部に「Recipe As Output」を作成し、その中に入力を含めます。既存のRecipe As Outputがある場合は置き換えられますが削除はされません。
- 関連実験にアップロード:関連する構造(例:ロット)にファイルをアップロードします。
ステップ4―パーサーを選択する
次に、パーサーを選択します。パーサーはファイルの生テキストを読み取り、構造化された要素(ヘッダー、チャンネル、データ値)に分解し、システムが自動的に理解・処理できるようにします。
「ファイルのパーサー」フィールドで次のいずれかを選択します。
- General Parser:カスタムパーサーが構築されていない場合、通常はGeneral Parser(general_parser)を使用します。このパーサーは設定可能です。
- Other Parsers:事前設定されたその他のオプションも利用できます。例えば、ファイルにヘッダーのないチャネルが含まれる場合に使用できる「format_unlabeled_channels」などがあります。
- Custom Parser:ファイルがGeneral Parserで処理できない場合、カスタムパーサーを構築する必要があります。
File Parserの横にある歯車アイコンをクリックすると、さまざまな追加の解析ツールにもアクセスできます。詳細はこちら。
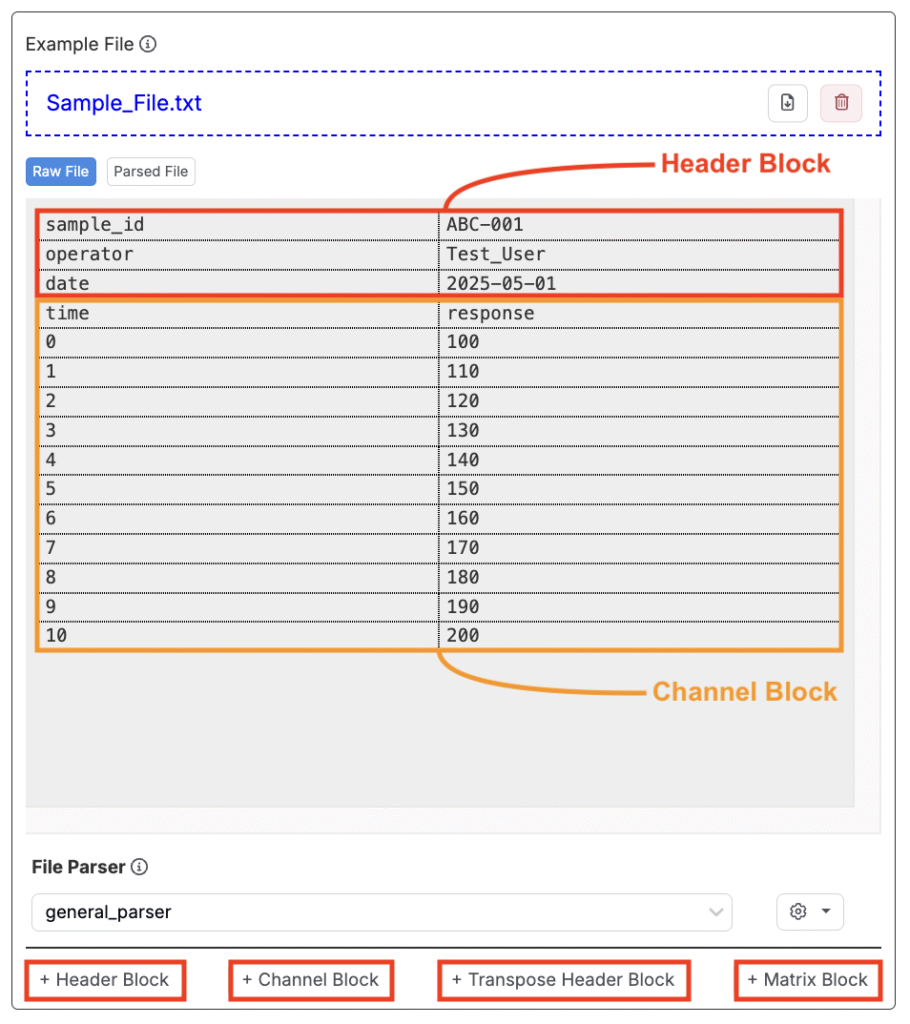
ステップ5―ヘッダー/チャネルブロックを解析する
Uncountableに正しい値を取り込むには、ファイルのどの部分がヘッダー情報を含み、どの部分がチャネルデータを含むかを定義する必要があります。
「アップローダーを編集」ページで「生ファイル」タブを使用し、ヘッダーとチャネルのブロックを特定します。その後、次のボタンを使ってブロックを追加します。
- ヘッダーブロック:ヘッダーフィールドが横方向に表示されている場合に使用します。
- チャンネルブロック:データ列(例:曲線や数値配列)に使用します。
- ヘッダーブロックを転置:ヘッダーフィールドが縦方向に表示されている場合に使用します。
- マトッリクスブロック:典型的なチャネルやヘッダー形式に当てはまらないグリッド形式のデータに使用します。
ブロックを追加したら、「Parsed File」タブを使用して情報が正しく解析されているか確認し、必要に応じて更新します。
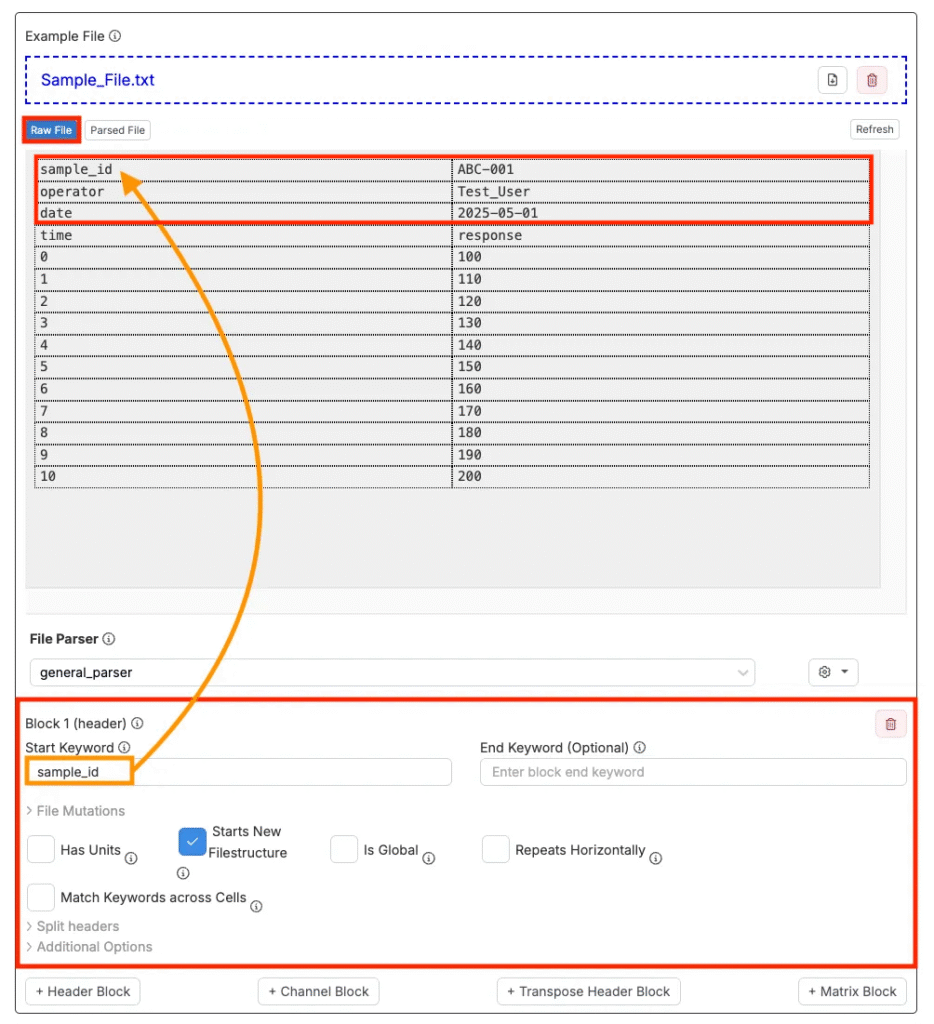
ヘッダーブロックの追加
ヘッダーブロックを使用すると、アップローダーはファイルから個々の「フィールド:値」ペアを取得し、それぞれを別々のアウトプットとして扱います。ヘッダーブロックは、最初のセルをフィールド名、2番目のセルを値、3番目のセルを単位(単位自体が存在し、「単位あり」がチェックされている場合)として抽出します。
ヘッダーブロックは、次の手順で追加します。
- [+ ヘッダーブロック]をクリックします。
- 「キーワード開始」を追加します(ヘッダーセクションの開始を示す最初のテキスト)。
- 「キーワード終了」を入力します(ヘッダーがデータ開始前に終了する場合、任意)。
- 次のヘッダー設定を行います。
- 「単位あり」:チャネル名のすぐ下に単位を含む行がある場合にチェックします。有効にすると、アップローダーはその行をデータとして解釈せずスキップします。
- 「新しいファイル構造を開始」:チェックすると、このブロックは新しいファイル構造を開始します。未チェックの場合、データは同じ構造の一部(1つの長い連結チャネル)として扱われます。
- 「グローバル?」:ファイルに複数のファイル構造が含まれる場合、この設定により、生成されたすべてのファイル構造にヘッダーブロックが挿入されます。
- 「水平方向に繰り返す」:ヘッダーブロックが横方向に繰り返される場合に有効にします。
- 「セル間にキーワードをマッチさせる」:チェックすると、キーワードは行全体ではなくセル間での一致が行われます。
- 「開始インデックス」:最初の指定列数を無視するために使用します。ヘッダーが最初の行から始まらない場合に便利です。デフォルト値は0です。
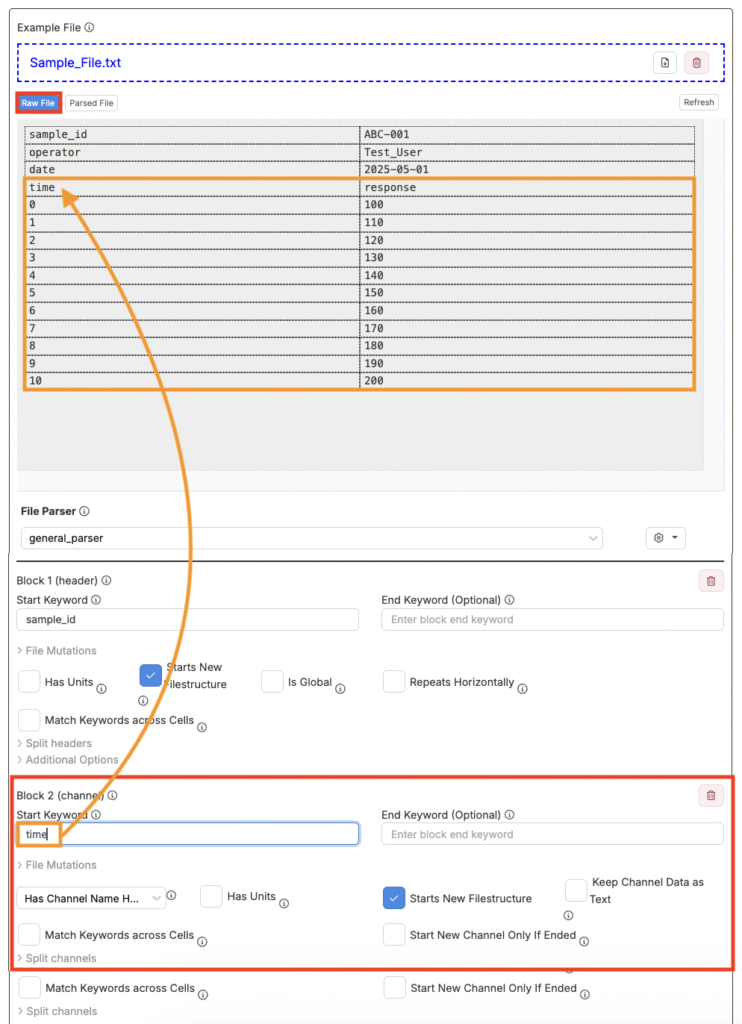
チャンネルブロックの追加
チャネルブロックは、2列以上(通常はX列とY列)を取り込み、1つの全体的なチャネルに変換します。
チャネルブロックは、次の手順で追加します。
- [+ チャンネルブロック]をクリックします。
- 「キーワード開始」を入力します(通常は最初の列ヘッダー)。
- 「キーワード終了」を入力します(データがファイルの終わりより前に終了する場合、任意)。
- 次のチャネル設定を行います。
- 「ヘッダー」:「No Header」、「Has Associated Header」、「Has Channel Header」のいずれかを選択します。
- 「単位あり」:チャネル名のすぐ下に単位を含む行がある場合にチェックします。有効にすると、その行はデータとして解釈されずスキップされます。
- 「新しいファイル構造を開始」:チェックすると、このブロックは新しいファイル構造を開始します。未チェックの場合、データは同じ構造の一部(1つの長い連結チャネル)として扱われます。
- 「チャネルデータをテキストとして保持する」:チェックすると、数値やタイムスタンプを含むすべてのデータがテキストとして解析されます。
- 「セル間のキーワードをマッチさせる」:チェックすると、キーワードは行全体ではなくセル間で一致します。
- 「終了した場合にのみ新しいチャネルを保持する」:有効にすると、ブロックは明示的に終了した場合、または新しいブロックが開始された場合のみ再開されます。
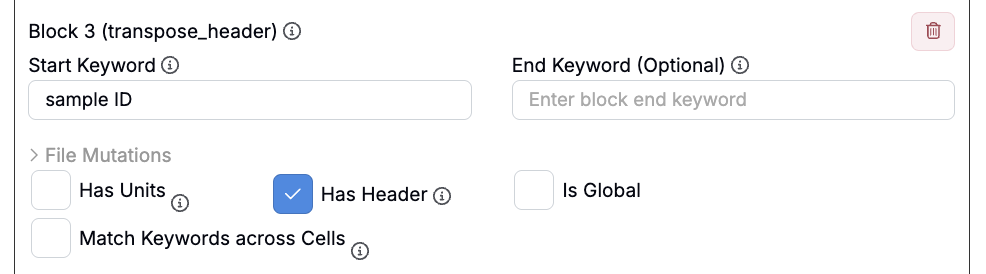
ヘッダーブロックを転置の追加
ヘッダー値が横方向ではなく縦方向に並んでいる場合、「ヘッダーブロックを転置」を使用して正しく抽出します。transpose_headerを使うと、次のような表形式データを解析できます。
- 列がヘッダー名を表している。
- 各行が個別のファイル構造に対応している。
- 各セルが関連するヘッダーの値を含んでいる。
この構造は、1つのテーブルに複数のサンプルやレプリケートが含まれ、各データ項目ごとに1行が割り当てられる場合に特に便利です。


ファイルミューテーション
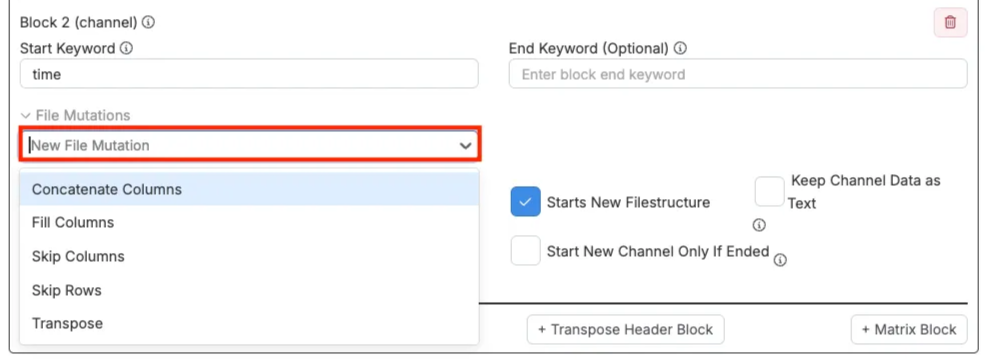
各ヘッダーまたはチャネルブロックには「ファイルミューテーション」設定があり、アップローダーがブロックを読み取る方法を調整できます。次のオプションがあります。
- 「Concatenate Columns」:複数の列を1つに結合します。値が複数列に分割されている場合に便利です。
- 「Fill Columns」:列内の空セルを直前の値で埋めます。ラベルがグループの先頭にのみ記載されている場合に役立ちます。
- 「Skip Columns」:不要な特定の列を無視します。
- 「Skip Rows」:開始キーワードの後に指定した行数をスキップします。データが数行下から始まる場合に便利です。
- 「Transpose」:ブロックを反転し、行を列に、列を行にします。主にマトリックスや回転レイアウトで使用されます。これらの設定は、データが解析される前にクリーンアップや再構成を行うのに役立ちます。
ブロックの追加が完了したら、すべてのファイル情報が「ファイルのパーサー」タブ内で正しく整理されているはずです。
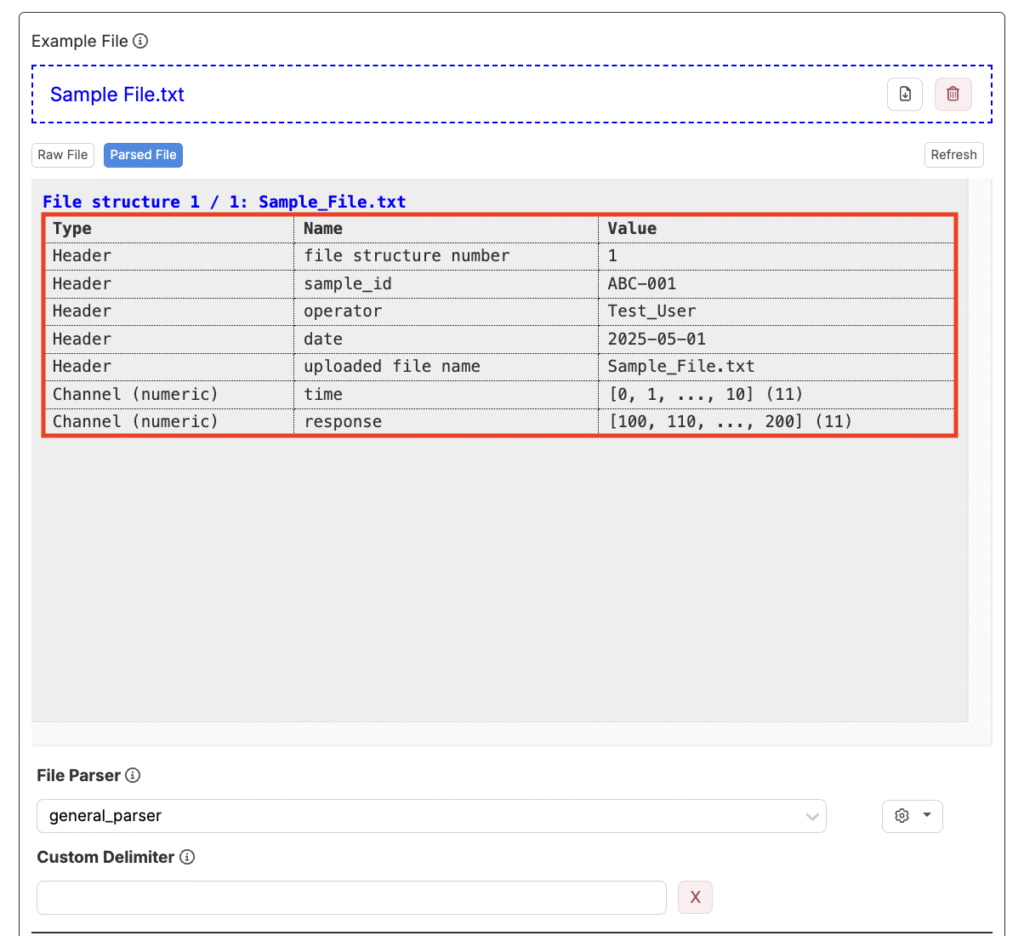
ステップ6―ヘッダー/チャネルブロックをデータにマッピングする
ファイルの解析はプロセスの一部に過ぎません。解析によってコンテンツがヘッダーや列に整理されますが、そのデータが実際に何を意味するのかを Uncountableに伝えることはできません。
「アップローダーを編集」ページの「抽出データ」セクションでは、解析された各データが何を意味し、システム内のどこに配置されるべきかを決定します。データをアウトプット、インプット、条件パラメータ、メタデータなどに抽出するためのタブがあります。
チャンネルをアウトプットにマッピングする
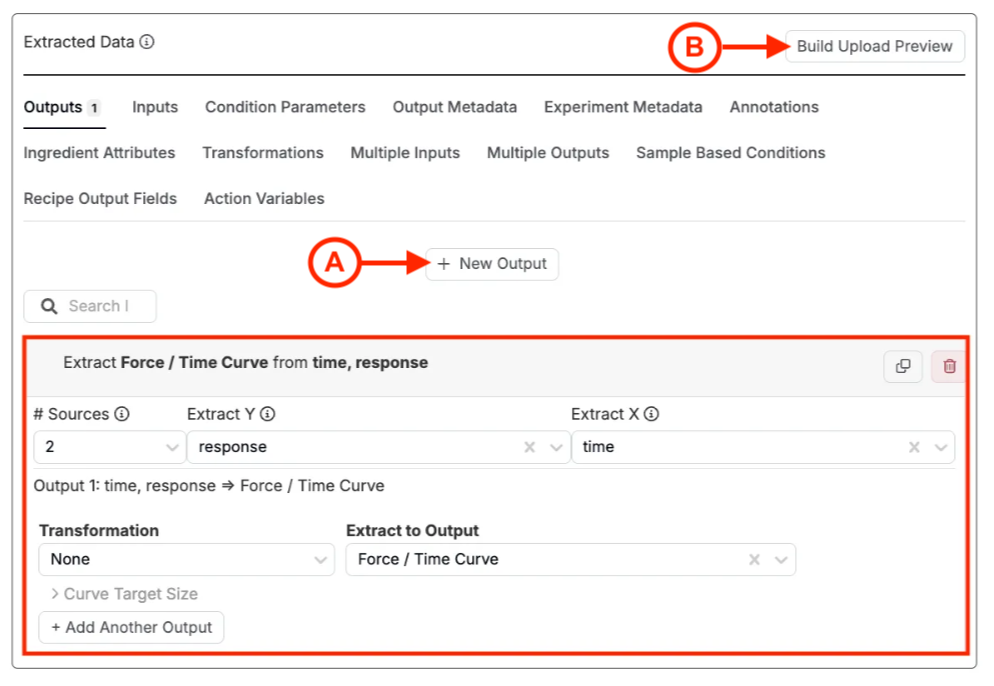
ほとんどの作業は「Outputs」タブで行います。ここでは、ファイル内で測定結果を表すすべての項目を定義します。
- 「抽出データ」セクションの「Outputs」タブをクリックします。
- [+新規アウトプット](A)ボタンを選択します。
- 「# Sources」を設定します。これは、アップローダーが取得するチャンネル数です。通常、数値出力を抽出する場合は1ソース、曲線出力を抽出する場合は2ソースを使用します。
- 「ファイル/ソースから抽出」または「抽出 X/Yフィールド」でソースを選択します。これらは「ファイルのパーサー」タブに表示されるチャネルの「Name」列と一致する必要があります。
- 必要に応じて「変換」を追加します(最小値、最大値、加重平均など)。これはチャンネルデータを保存する前に処理するためのものです。詳細はこちら。
- 「アウトプットに抽出」フィールドを使用して、Uncountableがデータをどこに送信するかを指定します。既存の出力を選択するか、このフィールドから新しい出力を直接作成できます。
- 作業中は[プレビューのアップロードを構築](B)を使用して確認します。なお、この機能はアウトプットのテストには使用できますが、アウトプットメタデータのテストには使用できません。
ファイルをアウトプットとして追加
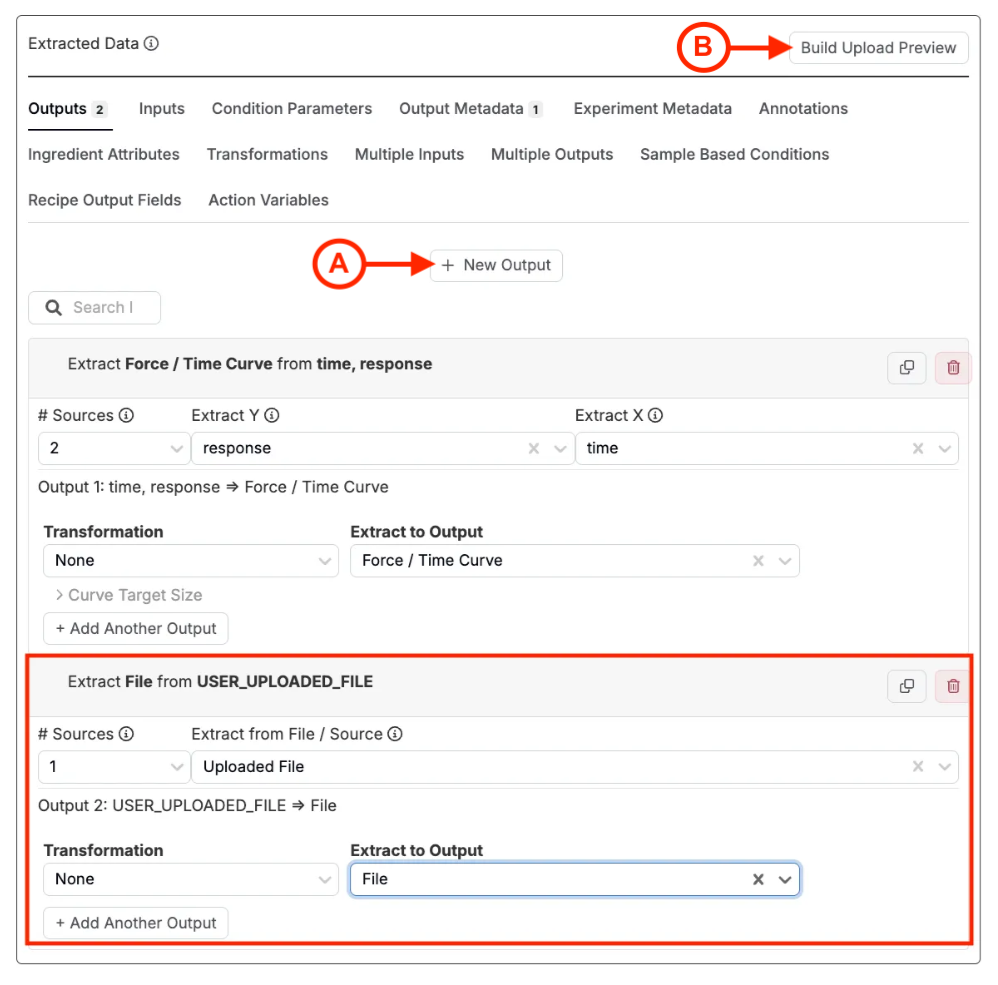
Uncountableの処方に、元の機器ファイルをファイルアウトプットとして自動的に含めたい場合、アップローダーの設定時にこれを実現できます。
- 「抽出データ」セクションの「Outputs」タブをクリックします。
- [+新規アウトプット](A)ボタンを選択します。
- 「# Sources」を1に設定します。
- 「ファイル/ソースから抽出」フィールドで「アップロード済みのファイル」を選択します。
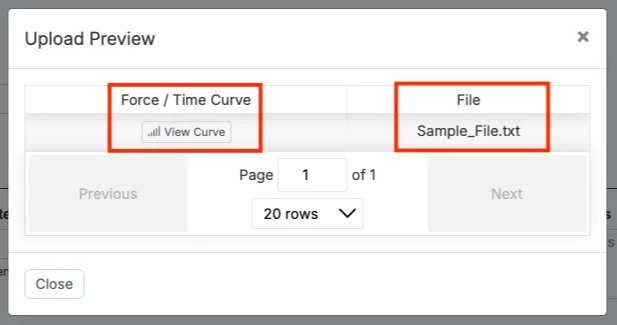
- 「アウトプットに抽出」フィールドでファイルタイプのアウトプットを選択します。
- [プレビューのアップロードを構築](B)を使用して設定を確認します。
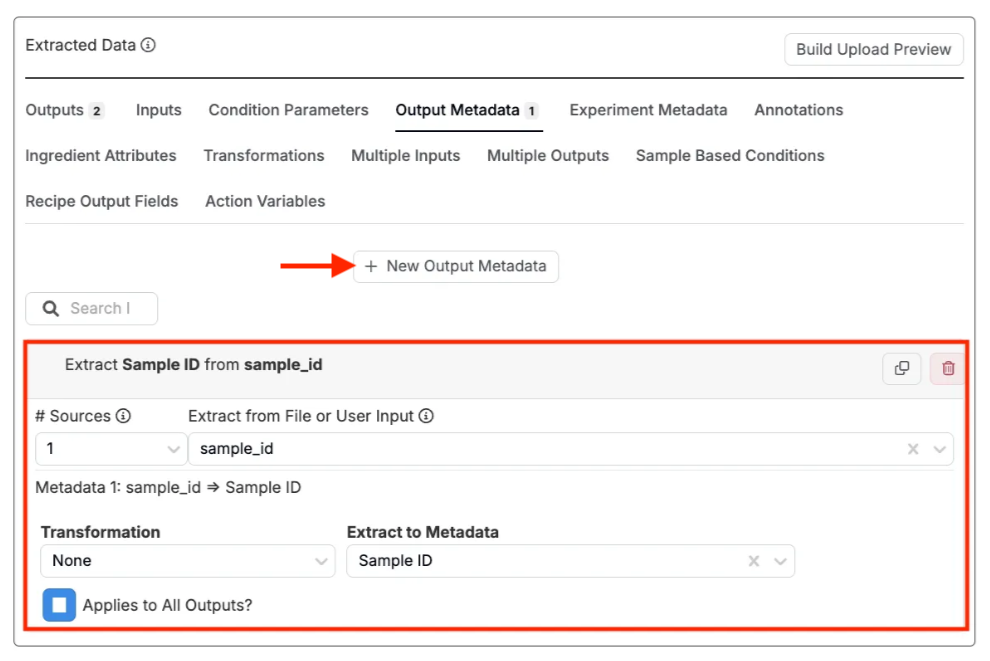
ヘッダーをアウトプットメタデータにマッピング
「Output Metadata」タブでは、値を手動で入力するか、ヘッダーからフィールドをマッピングしてアウトプットメタデータを定義できます。
- 「抽出データ」セクションの「Output Metadata」タブをクリックします。
- [+ New Output Metadata]ボタンを選択します。
- 「# Sources」を1に設定します。
- 「ファイルまたはユーザーインプットから抽出」フィールドを使用してソースを選択または入力します。
- 「Extract to Metadata」フィールドを使用して、新しいメタデータフィールドまたは既存のメタデータフィールドに抽出します。
ステップ7―追加の条件
「追加の条件」セクションでは、プレビューアップローダーモーダルで必須または入力を促す条件を追加できます。
- 必須:選択された条件パラメータは、送信前にプレビューアップローダーモーダルで値を入力する必要があります。
- 警告:選択された条件パラメータは、プレビューアップローダーモーダルで入力を促されます。

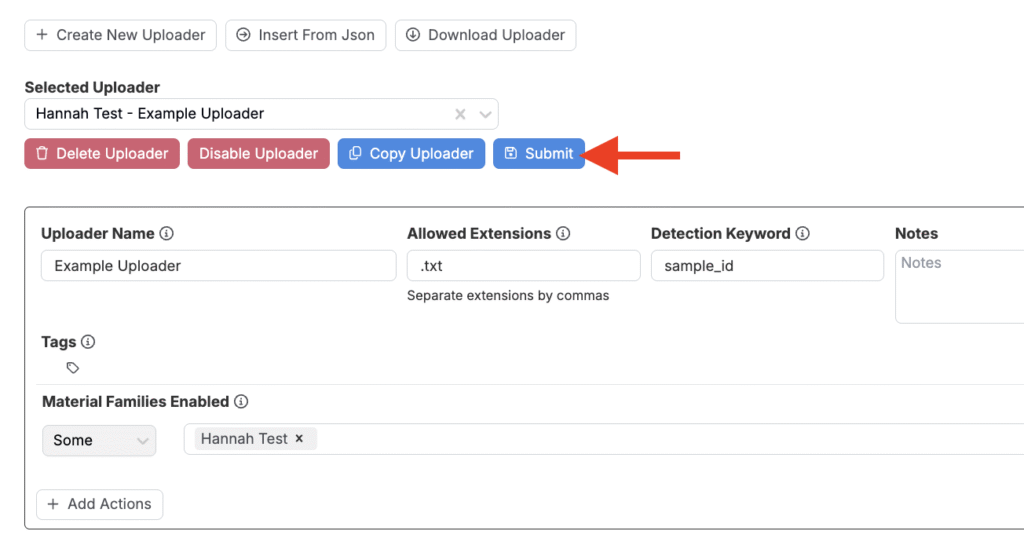
ステップ8―アップローダーを保存する
すべてのブロックをマッピングし、すべての設定を完了したら、「アップローダーを編集」ページの上部または下部にある青色の[+送信]ボタンをクリックします。
ステップ9―処方をテストする
最後に、新しいアップローダーをテスト用処方で試すことが重要です。
- テスト用処方の「アウトプット」ページに移動します。
- 上部ツールバーの[Upload Data]ボタンをクリックします。
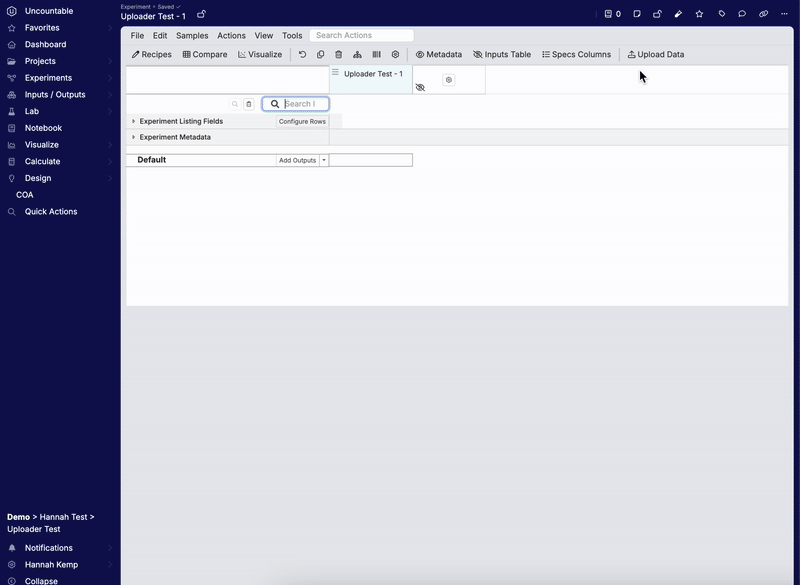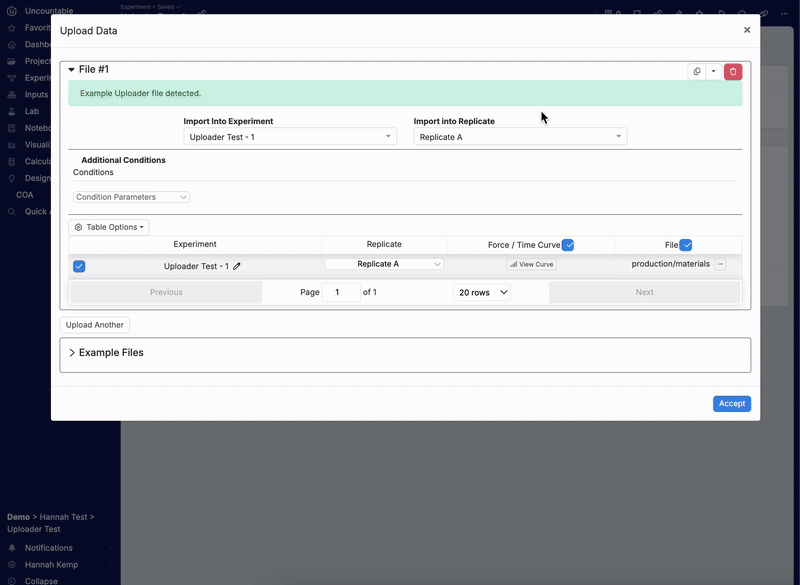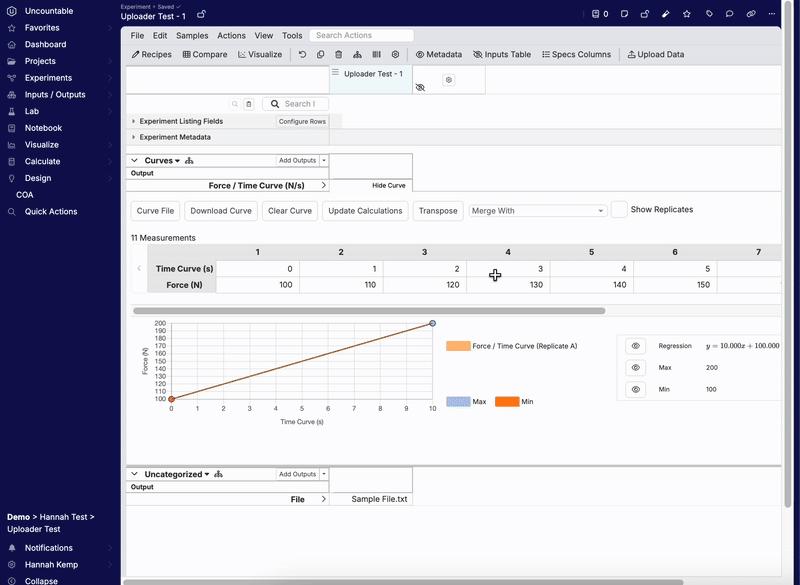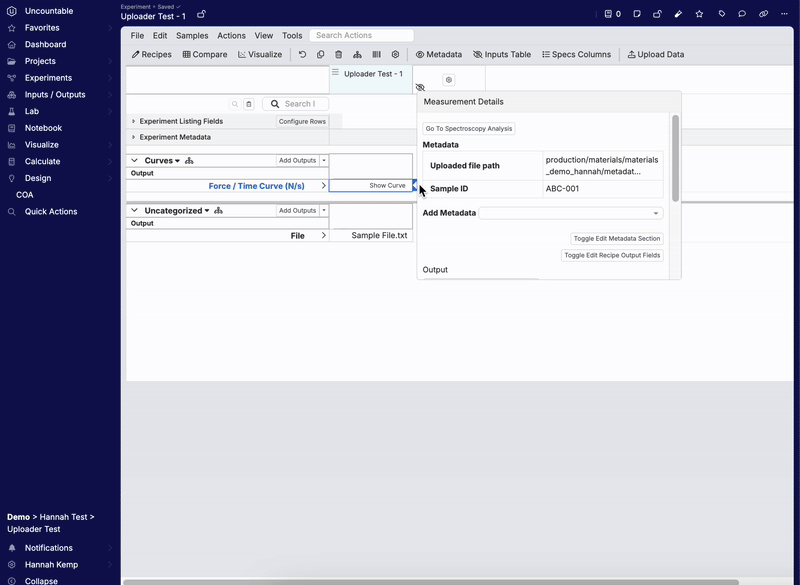
- サンプルファイルをドラッグ&ドロップします。
- アップローダーが自動的にマッチしない場合は、ドロップダウンメニューから選択します。
- [承諾]をクリックして、データをテスト用処方に読み込みます。
- 「アウトプット」ページで、すべてのアウトプットが正しく追加されていることを確認します。
参考記事
アップロードについては、次の記事もご覧ください。
- アップローダー(一般情報とFAQ)
- アップローダーのリクエスト
- 高度なアップローダー設定