ここでは、高度なアップローダー設定ツールと設定について説明します。マッピングについて詳しくは、アップローダーを設定するを参照してください。
ファイル解析ツール
一般的な解析アップローダーを設定する場合、設定の歯車アイコンのオプションを使用して、ファイルをヘッダーやチャンネルに対して抽出可能なセルに分割できます。

以下のオプションがあります。
- カスタム区切り記号:行の値の分割に使用する文字を手動で定義します(CSVの場合
,、TSVの場合\\t、また;や|も一般的です)。 - カスタムファイルタイプ:ファイル構造がデフォルトのタイプと異なる場合にファイル拡張子を上書きします。
- 行の正規表現をスキップ:いずれかのセルがregexパターンに一致する行をスキップします。たとえば、「n.a.」または「-」を含む行をスキップするには、次のRegexパターンを使用します。
(n\\.a\\.|^-$) - 行の正規表現を含める:指定したregexパターンに一致する行のみを含めます。
- シートの正規表現をスキップ:Excelファイルでタブ名がregexパターンに一致するタブ名のシートをスキップします。たとえば、Regexパターン
(samples|summary)の場合、名前が「samples」または「summary」のシートがスキップされます。 - エンコーディング:ファイルのテキストエンコーディング(
utf-8など)の手動選択を可能にします。地域固有のファイルの場合は、日本語や中国語などのエンコーディングを使用します。 - 入れ替え:ファイルのレイアウトを反転します。行を列に、列を行に変換します。データが縦方向に保存されている場合に便利です。
- 垂直分割区切り文字:1つの列内に積み重ねられた値を分割するための区切り文字を指定します。
注記:正規表現を使用する際、Regex101.comを利用すると便利です。
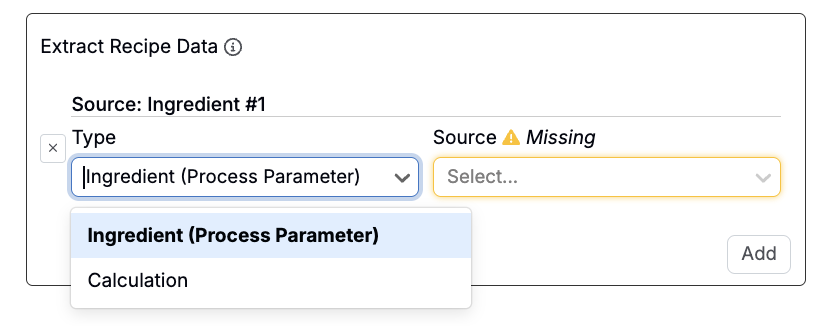
処方データを抽出する
「方策データを抽出」セクションでは、アップロード先の処方から値を直接取得できます。抽出できるのは、原料(工程条件)または計算値で、解析や変換の際に使用できます。
よくある使い方として、処方で定義されたパラメータを使ってアップロードされたカーブデータをトリミングすることが挙げられます。たとえば、このセクションを使用して、処方で指定された特定の時間に基づいて時間軸のカーブを制限できます。
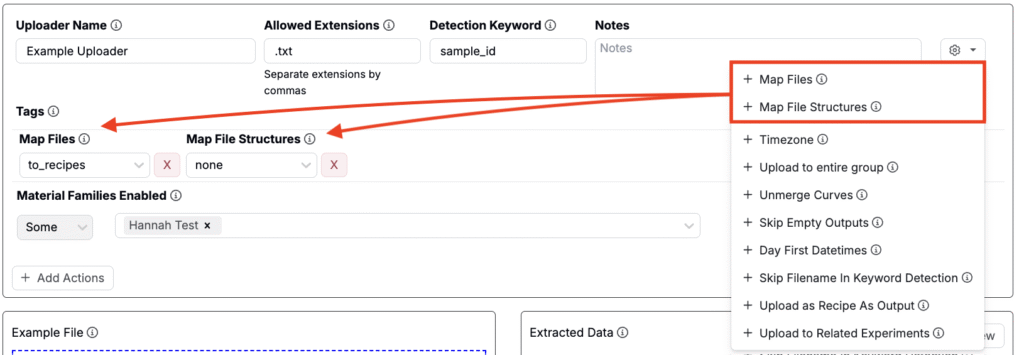
ファイルとファイル構造のマッピング
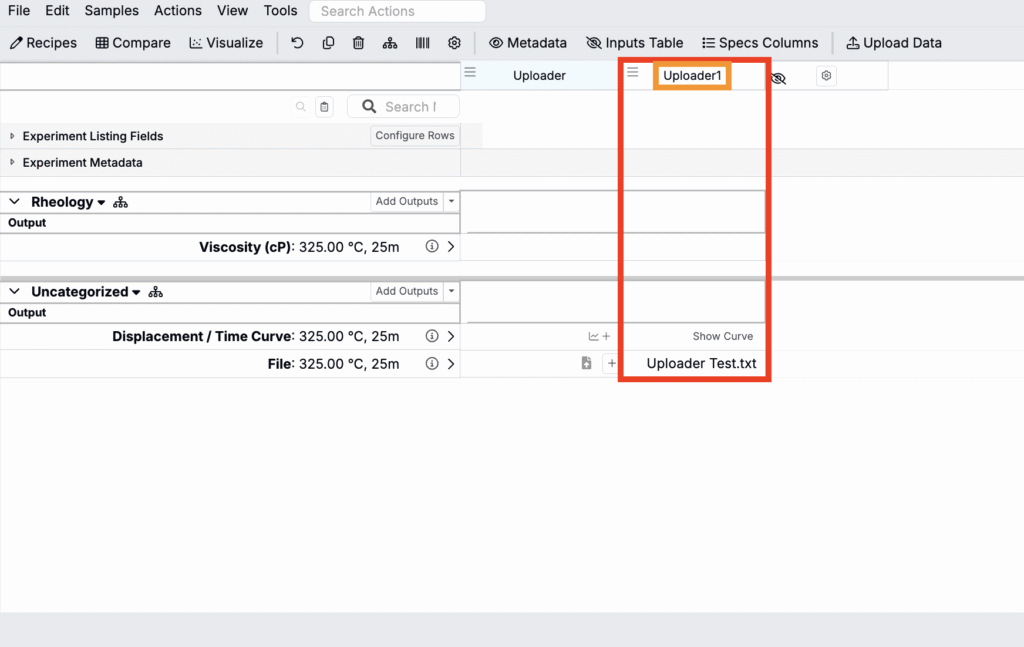
アップローダーを設定すると、同じタイプの複数ファイルを同時にアップロードできます。各ファイルには、1つまたは複数のファイル構造を含めることができます。デフォルトでは、Uncountable は次のようにマッピングします:
- 各ファイル → 処方へ
- ファイル内の各ファイル構造 → その処方の複数実験へ
このマッピングの動作は、アップローダーの設定メニュー(歯車アイコン)にある「マップファイル」および「マップファイルの構造」オプションでカスタマイズできます。フィールドをアップローダーに追加した後、それぞれを処方、複数実験、カスタム、または、なしのいずれにマッピングするかを選択します。
- to_recipes:各ファイルまたはファイル構造を新しい処方にマッピングします。
- to_replicates:各ファイルまたはファイル構造を同じ処方の複製にマッピングします。
- custom:「マップファイル」と「マップファイルの構造」の両方が「Custom」に設定されている場合、より複雑なマッピングロジックを作成できます。詳しくは以降のセクションを参照してください。
- none:すべてのマッピングロジックを削除します。
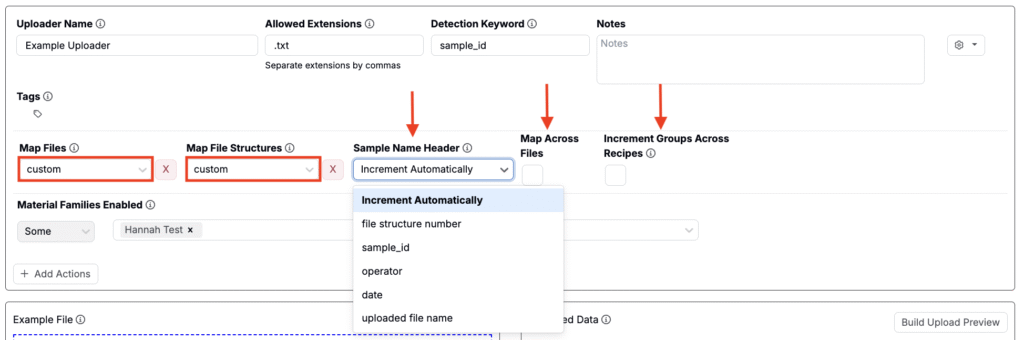
サンプル名ヘッダを使用したカスタムマッピング
「マップファイル」と「マップファイルの構造」の両方のオプションが「custom」に設定されている場合、新しい設定項目が表示されます。
- サンプル名のヘッダー:抽出されたメタデータに基づいてグループ化を制御するための設定です。選択できるオプションは次のとおりです:
- 自動的に増分(デフォルト):各ファイル構造は独立して扱われ、グループ化は行われません。
- メタデータフィールド:抽出されたメタデータフィールドのいずれかを選択します。このフィールドで値が一致するファイル構造は、同じ複製または実験にグループ化されます。
- ファイルすべてのマッピング:有効にすると、グループ化は個々のファイル内だけでなく、アップロードされたすべてのファイルに対して適用されます。これにより、異なるファイルに含まれるファイル構造を、共通のメタデータ値に基づいてまとめることができます。
- レシピ間でグループを増加:有効にすると、グループ化されたファイル構造が現在のビュー内の複数の処方に割り当てられます。これは、多くのグループをアップロードし、それらを選択した処方から順番に分配する場合に便利です。
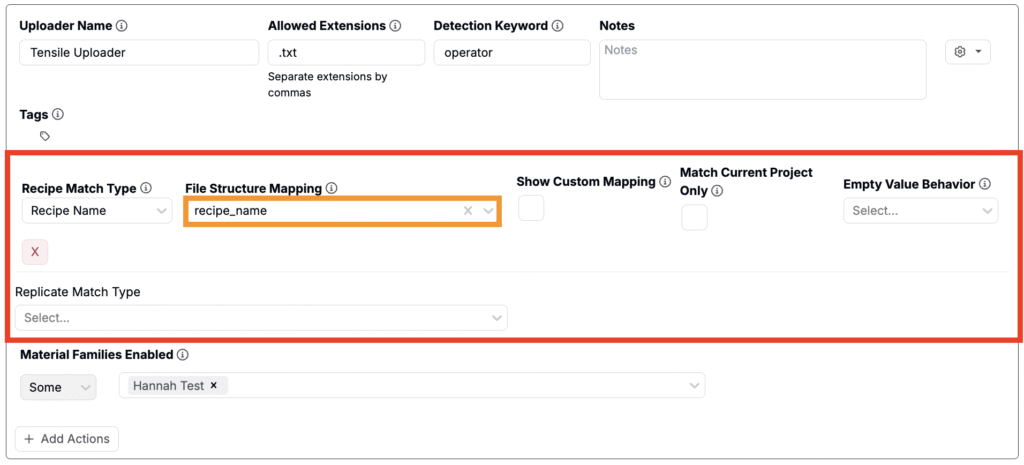
ファイル構造を特定の処方にマッピングする
Uncountableでは、「ファイル構造のマッピング」を有効にし、処方にマッチするロジックを設定することで、ファイル構造を特定の処方に自動的にマッピングできます。これを設定するには、次の手順を実行します。
- アップローダーの設定を開き、「ファイル構造マッピング」を追加します。
- 「ファイル構造マッピング」セクションで、次の設定を行います:
- 方策マッチタイプ:Uncountable内で照合するフィールドを選択します。選択肢は以下のとおりです:
- Recipe id
- Recipe Name
- Recipe Metadata
- Well plate
- Recipe Structured Filters
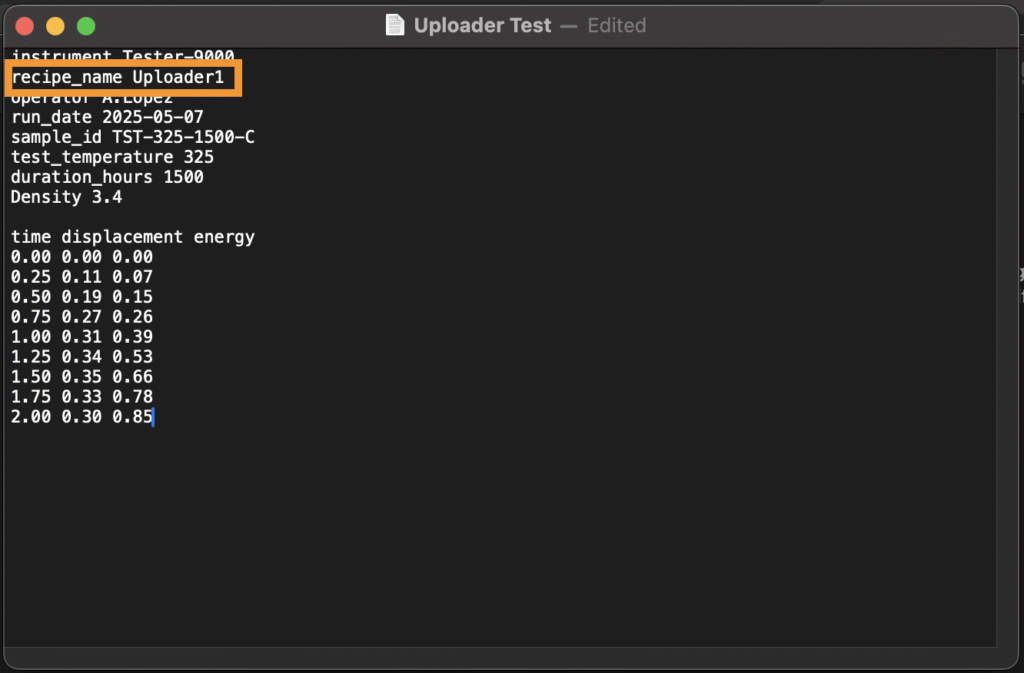
- Recipe Source:照合する値を含む解析済みヘッダーまたはチャンネルを選択します(例:ファイル内の「recipe_name」という列)。
- 方策マッチタイプ:Uncountable内で照合するフィールドを選択します。選択肢は以下のとおりです:
- 必要に応じて追加設定します:
- カスタムマッピングを表示:有効にすると、プレビューモーダルにカスタムマッピング手順が表示され、割り当ての確認や上書きが可能になります。
- 現在のプロジェクトのみにマッチさせる:有効にすると、現在のプロジェクト内の処方のみを対象に照合します。
- 空の値の動作:「Recipe Source」フィールドが欠落または空の場合の処理方法を選択します。
- マッチタイプを反復:一致した処方で複製をどのように割り当てるかを選択します。
保存すると、Uncountableは選択したファイル元と選択した処方フィールドの完全一致に基づいて、ファイル構造を処方に自動的に割り当てます。なお、ファイル構造を割り当てるには、アップロード時に処方がビューに表示されている必要があります。
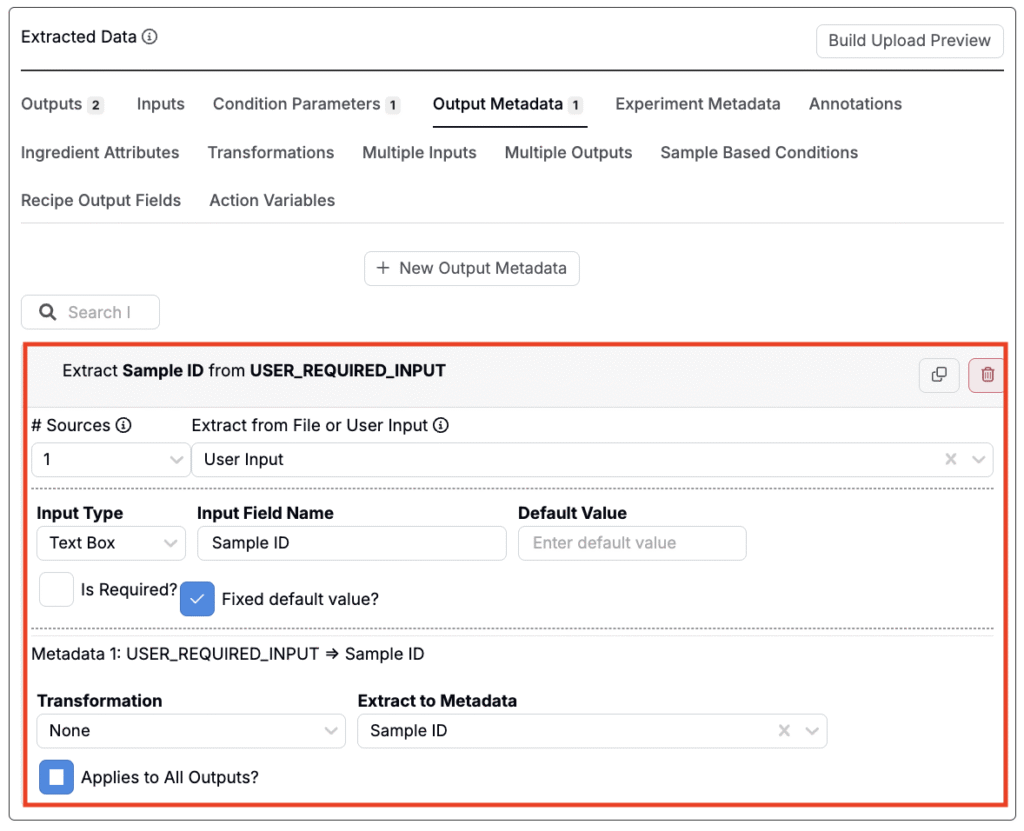
ユーザー入力フィールド
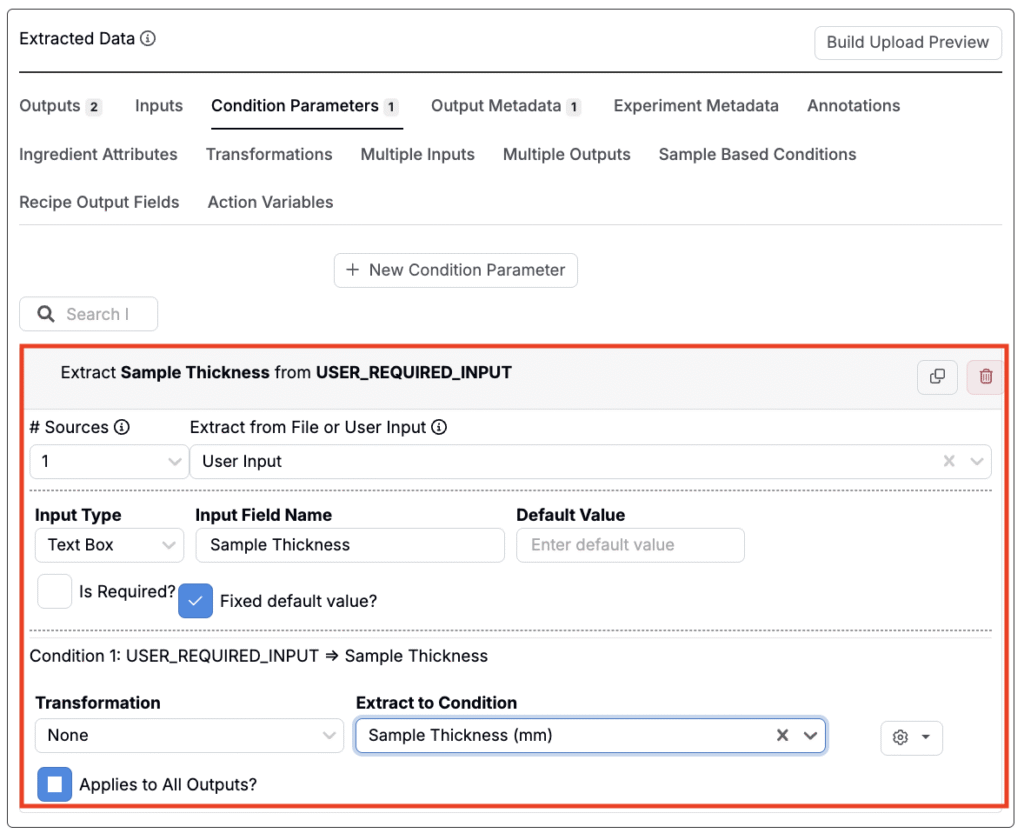
条件パラメータやアウトプットのメタデータを抽出する際、抽出データをユーザー入力に設定できます。これにより、ファイルのアップロード時にユーザーが必ず入力しなければならないフィールドを定義できます。ファイル自体に値が含まれていないが、正しいデータマッピングに必要な場合に便利です。
たとえば、ユーザー入力はオペレーター、装置、バッチID、日付などのフィールドに使用できます。
関連して、以下の設定を行えます。
- インプットタイプ:入力形式を選択します。Text Box、Dropdown、Datetime.から選択できます。
- インプットのフィールド名:値の入力を促す際にユーザーに表示されるラベル名。
- デフォルト値:入力フィールドにあらかじめ表示される値(必要に応じてユーザーが変更可能)。
- 必須?:有効にすると、アップローダーを送信する前にユーザーが必ず値を入力する必要があります。
- デフォルト値の固定?:設定すると、フィールドに値があらかじめ入力され、ユーザーは編集できません。
- 変換:保存前に入力値にオプションの変換を適用します。
- Extract to Condition:インプット値を保存する既存の条件パラメータまたはアウトプットのメタデータフィールドを選択します。
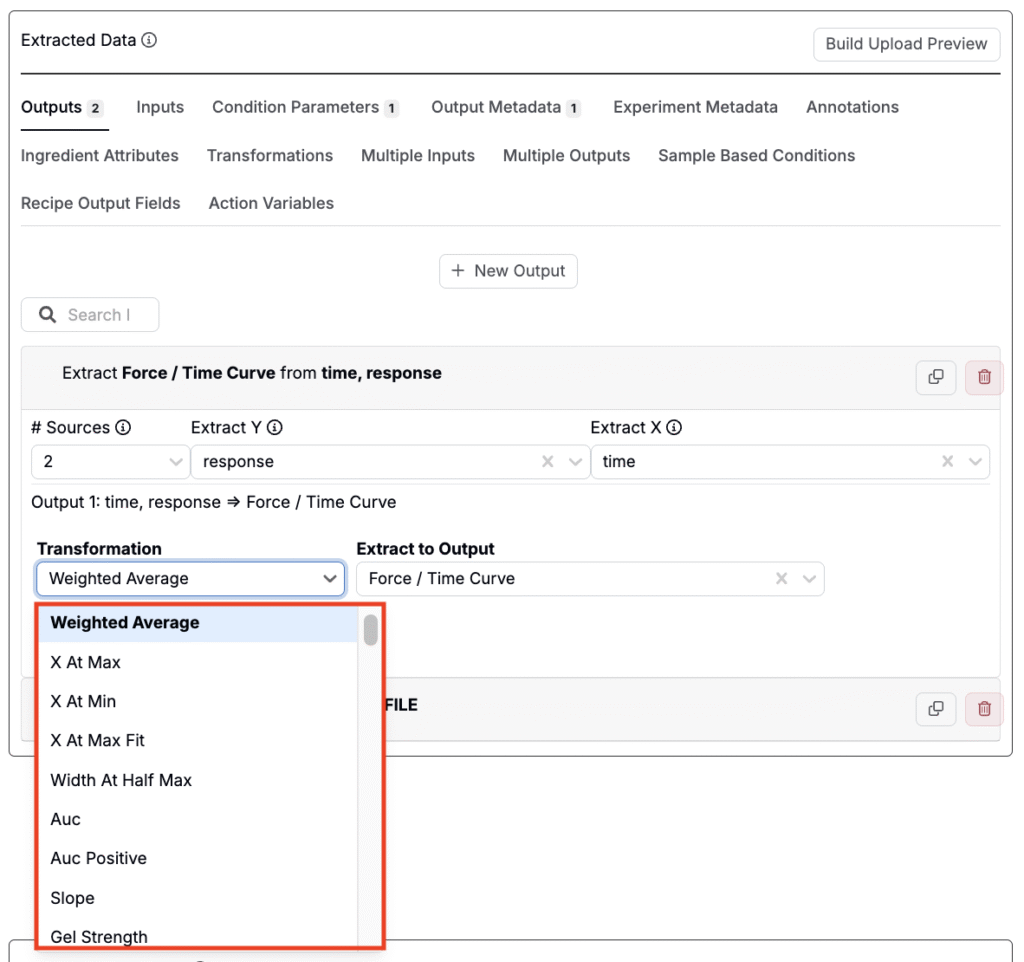
変換
ブロックをアウトプットにマッピングする際、「変換」フィールドを使用すると、抽出したデータに自動的に数式を適用できます。これは、アウトプットにマッピングする前にチャンネルを要約、再構成、またはクリーンアップしたい場合に便利です。
次のような操作が行えます。
- Min / Max:データセットから最小値または最大値を抽出します。
- Min Y / Max Y:最小Yまたは最大Yが発生するXの位置を取得します。
- Average / Weighted Average:平均値を返します。加重平均ではX値を考慮します。
- Slope:カーブの傾きを計算します。
- Remove Nulls:抽出前に空または無効なポイントを除外します。
- Curve Rounding:ノイズの多いデータをクリーンにするためにカーブ値を丸めます。
- Diff from Start X:最初のXポイントに対してYがどれだけ変化したかを返します。
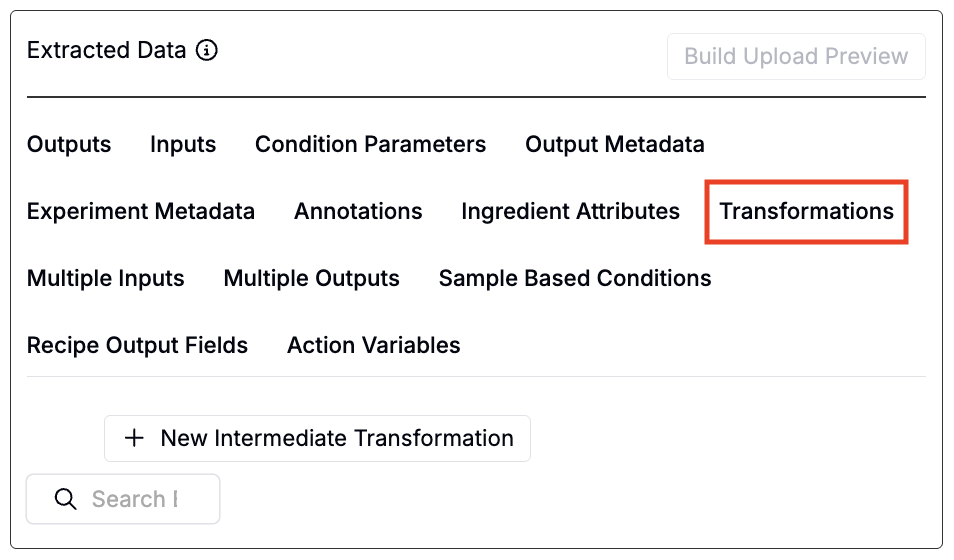
中間変換(「Transformations」タブ)
「Transformations」タブを使用して、中間変換を設定することもできます。中間変換は、複数の操作を連続して適用する必要がある場合や、変換後の結果を複数の抽出処理で再利用したい場合に使用します。